In this post, I would summarize key points from classic paper <BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding> following its initial structure.
Important Links
0. Abstract
Related work: GPT (Radford et al.) & ELMo (Peters et al.)
Fun fact: ELMo & BERT are both character name from Sesame Street
Difference between these two:
GPT - use left context for predicting future inputs <-> BERT - use both context
ELMo - RNN architecture, need architecture modification <-> BERT - Transformer Architecture, no task-specific architecture modifications needed for downstream tasks.
Advantages:
Conceptually simple
Empirically powerful (on specific tasks)
Writing tips: State both absolute and relative performance for reader understanding.
1. Introduction
Pre-training language model in NLP area (BERT reused pre-training technique from CV area, advocating later research to follow)
Extension to Abstract para 1. Existing strategies for applying pre-trained language representations
Feature-based - ELMo
Fine-tuning - GPT
Limitation on related work
Unidirectional language models restrict pre-trained representations.
- GPT’s left-to-right architecture, “every token can only at- tend to previous tokens in the self-attention layers of the Transformer”
BERT’s improvement: using bi-directional context & “masked language model”
Contributions:
Importance of bidirectional pre-training
Reducing task-specific architecture modification need
2. Related Work
2.1 Unsupervised Feature-based approach
ELMo & others.
2.2 Unsupervised Fine-tuning Approaches
GPT & others.
2.3 Transfer Learning from Supervised Data
3. BERT (Implementation)
Two steps in BERT’s framework: pre-training and fine-tuning.
Writing tips: Include a brief introduction of supplementary techniques used. (E.g. pre-training & fine-tuning here)
3.0.1 Model architecture
Multi-layer bidirectional Transformer encoder based on Vaswani et al.(2017) ‘s original implementation in this repo. Guide could be found in this article.
\(BERT_{BASE} \Rightarrow L=12,H=768,A=12,Total\ parameters=110M\)
This model is designed to have the same model size as GPT on comparison purposes.
\(BERT_{LARGE} \Rightarrow L=24,H=1024,A=16,Total\ parameters=340M\)
where,
- \(L\) - number of Transformer blocks
- \(H\) - Hidden size
- \(A\) - number of self-attention heads
In literature, bidirectional transformer is often referred to as a “Transformer encoder”
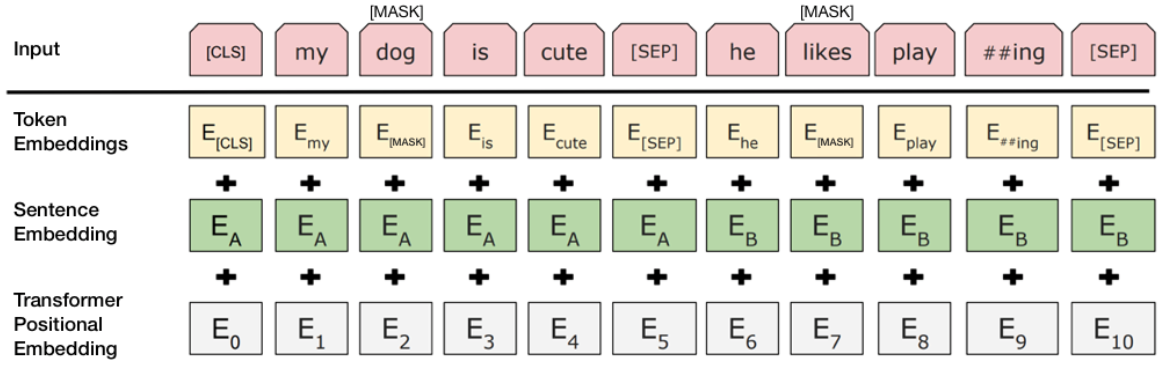
3.0.2 Input/Output Representations
Context
To cope with different down-stream tasks, input representation needs to unambiguously represent both a single sentence and a pari of sentences in one token sequence.
Important definitions
- Sentence - arbitrary span of contiguous text, rather than an actual linguistic sentence.
- Sequence - input token to BERT.
Implementation
WordPiece embeddings (Wu et al., 2016.) WordPiece embeddings cut word into smaller sub-sequence for low frequency words to reduce the size of token vocabulary.
Rules:
First token of every sequence =
[CLS]- Used for classification tasksPacking sentences
Separate using
[SEP](simple mark)Use a learned embedding - summing the token, segement and position embeddings.
3.1 Pre-training BERT
BERT’s pre-training uses two unsupervised tasks
- Masked Language Model (MLM)
- Next Sentence Prediction (NSP)
3.1.1 Task I: Masked LM
Intuition: Bring in contextual information (as ELMo suggests)
Task description
Mask some percentage of the input tokens at random, and then predict those masked tokens.
Task details
- Mask 15% of all WordPiece tokens in each sequence at random.
- To mitigate the mismatch (fine-tuning’s input has no
[MASK]token) between pre-training & fine-tuning, masked words are replaced in differently. If the i-th token is chosen, it is replaced with[MASK]token - 80% of the time- a random token - 10% of the time (to add noise into the training data)
- the unchanged token - 10% of the time
Online demo for this task
Check out huggingface’s online impelmentation of BERT base model.
Task idea origin
Cloze task by Taylor.
3.1.2 Task II: Next Sentence Prediction (NSP)
Intuition: capture sentence relationships for tasks like Question Answering & Natural Language Inference
Task description
Input two sentences A & B, output a binary label indicates whether B is the next sentence follows A.
Details
- Training data construction - 50-50 split of positive & negative samples.
3.1.3 Data source
For the pre-training corpus we use the BooksCorpus (800M words) (Zhu et al., 2015) and English Wikipedia (2,500M words). For Wikipedia we extract only the text passages and ignore lists, tables, and headers.
3.2 Fine-tuning BERT
Fine-tuning BERT is the process of reorganize the input sentence into sequence to model different downstream tasks. For each task, plug in the task-specific inputs and outpus is needed and BERT is finetuned end-to-end.
BERT’s fine-tuning is inexpensive. All of the results in the paper can be replicated in at most 1 hour on a single Cloud TPU, or a few hours on a GPU, starting from the exact same pre-trained model.
4. Experiments
Introduces the way to cope with and the results on different down-stream tasks. For the detail of input format modification and experiment result, please refer to the original paper.
- GLUE
- SQuAD v1.1
- SQuAD v2.0
- SWAG
5. Ablation Studies
In this section, ablation experiemnt over pre-training tasks, model size and feature-based approach are performed.
In summary, the ablation study shows
- all proposed pre-training tasks are necessary for improving the model’s performance.
- Increasing the model size coudl lead to continual improvements on large-scale tasks.
- Extracting fixed features from pre-trained model experiment result demonstrates BERT is effective for both fine-tuning & feature based approach
Research tips: It is good practice to perform ablation studies to add explainability to large scale models with different components. #Area/Research
6. Conclusion
Rich, unsupervised pre-training is crucial for language understanding.
Major contribution: “further generalizing these findings to deep bidirectional architectures, allowing the same pre-trained model to successfully tackle a broad set of NLP tasks.”
Limitation: Constrain on generation tasks as bidirectional .
Reflect
- Which two former work does BERT mainly refer to? What’s the advantage(s) of each prior work? What is BERT’s main contribution/innovation compared to those work?
- Which two kinds of tasks is BERT divided into?
- Which two kinds of tasks is BERT’s pre-training divided into? What’s the effect of each task?
- What is the advantage and disadvantage of BERT?