In this post, I would summarize key points from classic paper
Important Links
Acknowledgements
Special thanks to Mu LI, who provides a wonderful review video on this article.
Also thanks to Lilian, for this wonderful blog connecting transformer's principle & applications.
0. Abstract
- Paper proposes a new simple network architecture, the Transformer, based solely on attention mechanisms
- State-of-the-art result on machine translation tasks
- Advantages of transformer architecture
- More parallelizable & require significantly less training time
- Generalize well to other tasks - see BERT, GPT
Writing tips
When stating equal contribution using
*, it's good practice to list briefly about each member's work done.
1. Introduction
Basically an extension to abstract
Recurrent neural networks /models'
Principle Generate a sequence of hidden states \(h_t\), as a function of the previous hidden state \(h_{t−1}\) and the input for position \(t\).
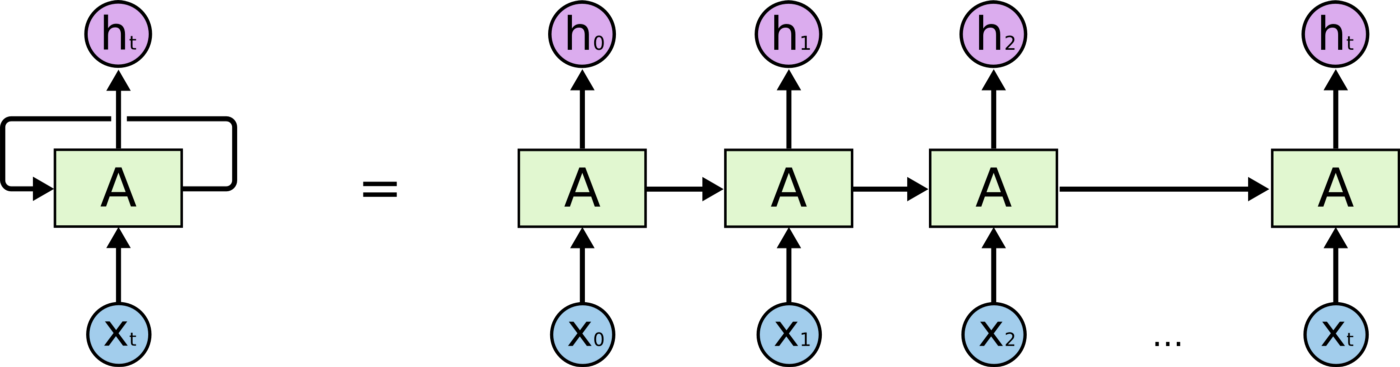
Drawbacks
- Parallelization preclusion by calculation method
- High memory requirements for preserving historical information. / Possibility in forgetting early information after step by step passing.
Attention Mechanism
- An integral part of sequence & transduction models.
- Allow the model to capture dependencies between in/out sequence regardless of their distance.
- Most of them used in conjunction with a recurrent network
Transformer's innovation
- “eschewing recurrence and instead relying entirely on an attention mechanism”
2. Background
- Introduces previous attempts to reduce sequential computation -
using CNN (convolutional neural networks)
- “difficult to learn dependencies between distant positions”, between long sequences
- Why Multi-Head Attention (instead of single head)?
- Attention mechanism eschewed convolution mechanism, losing the opportunity to model different patterns.
- Using Multi-Head Attention mechanism is to simulate the multi-channel output of CNN.
- Previous success on self-attention
- End-to-end memory networks’ scope and performance
- Innovation point about Transformer.
3. Model Architecture
Follows most competitive sequence transduction models, Transformer uses an encoder-decoder structure, where
- Encoder maps input sequence to a vector-like representation for model usage.
- Decoder generates output sequence one element at a time.
The model is auto-regressive, using output from previous moment as additional input.
3.1 Encoder & Decoder Stacks
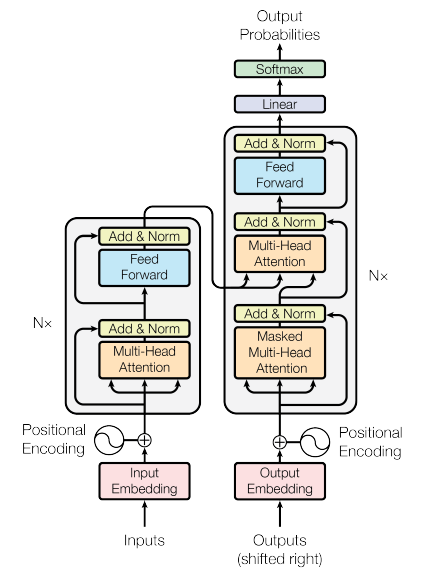
- Encoder - Decoder, shown in the left and right halves respectively.
- Each layer of encoder consists of two sub-layers -
a multi-head attention mechanism & a MLP. The residual connection
(inspired by ResNet) is used within sub-layers. The
LayerNorm technique is also implemented.
- LayerNorm is a different normalization method from Batch Normalization and is more suitable with models taking variable-length inputs (temporal sequences), reducing the impact of different batch cuts (sequence length variations) on normalization.
- Generally speaking, the difference lies in the data slicing mechanism. BN slices the data according to the batch and regularizes the feature dimensions, while LN slices the data according to the input samples and regularizes different features of the same sample.
- In addition to encoder, decoder adds another layer, calculate the multi-head attention over the output of the encoder. A masking mechanism is used to prevent decoder uses output after position \(i\) to predict the position \(i\).
3.2 Attention
Attention is a mechanism that model learns to make predictions by selectively attending to a given set of data.1
Self-attention is a type of attention mechanism where the model makes prediction for one part of a data sample using other parts of the observation about the same sample,... it is permutation-invariant; in other words, it is an operation on sets.1
- In transformer's Encoder, Query, Key, Value are identical vectors generated by the embedding layer, therefore no trainable variables involved.
“An attention function can be described as mapping a query and a set of key-value pairs to an output. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.”
The amount of attention is quantified by learned weights and thus the output is usually in the form of weighted average over input (Query, Key, Value) pair.
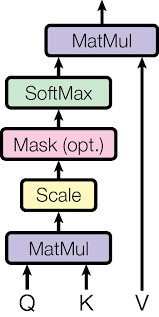
3.2.1 Scaled Dot-Product Attention
- What's Dot-Product?
- Perform matrix multiplication on queries (Q) and keys (K) embeddings.
- Why Dot-Product?
- Faster & space-efficient in practice
Another alternative for attention functions are additive attention.
- What's Scale?
- After dot-product, divide the result by \(\sqrt{d_k}\).
- Why scale?
- For long input sequence, apply
softmaxon the unscaled dot-product could result in Vanishing gradient.
- For long input sequence, apply
\[ Attention(Q,K,V) = \text{softmax}(\frac{QK^T}{\sqrt{d_k}})V \]
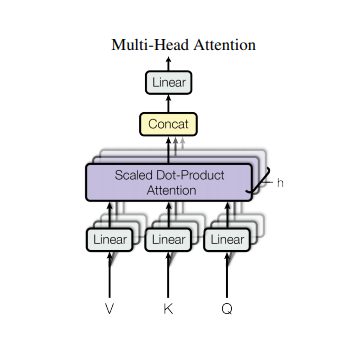
3.2.2 Multi-Head Attention
What is Multi-head attention?
 \[
\begin{aligned}
\text{MultiHead}(Q,K,V) = \text{Concat}(head_1,...,head_h)W^O \\
where\ head_i=\text{Attention}(QW_i^Q,KW_i^K,VW_i^V)
\end{aligned}
\]
\[
\begin{aligned}
\text{MultiHead}(Q,K,V) = \text{Concat}(head_1,...,head_h)W^O \\
where\ head_i=\text{Attention}(QW_i^Q,KW_i^K,VW_i^V)
\end{aligned}
\]
Why multi-head?
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions
- Just like CNN's different convolution kernel, multi-head attention enables the model to capture different input patterns, learning more representations.
3.2.3 Applications of Attention in our Model
- In "encoder-decoder attention" layers, the queries come from the previous decoder layer, and the memory keys and values come from the output of the encoder.
- The encoder contains self-attention layers
- The decoder contains self-attention layers.
3.3 Position-wise Feed-Forward Networks
Put it in other way - it's a fully-connected feed-forward network with one hidden layer (MLP).
This layer applies a linear transformation (\(xW_1+b_1\)) on input x, using
a ReLU activation function and then another linear transformation.
One thing to notice - the first transformation expand the input dimension to \(2048\), and then project it back in the second transformation. \[ FFN(x) = \max(0, xW_1+b_1)W_2+b_2 \]
- What is position-wise?
- the above linear transformation is applied to every position of the output separately and identically.
- To put it in simple ways, it is applied to each word of the input sequence, and is therefore called point-wise
Comparison between transformer & RNN
Transformer extracts sequence information when applying attention function, while the RNN directly passes the \(t-1\) information to the next computing block.
3.4 Embeddings and Softmax
- What's embedding?
- Embedding are a vector form of input token, used to represent semantic information.
In Transformer, embeddings are used for inputs of both encoder and decoder. Same weight matrix are applied for these embeddings and pre-softmax linear transformation.
- Why multiply \(\sqrt{d_{model}}\)
in embedding layer?
- When learning embeddings, the L2 Norm value is applied. With the increase of input dimension, the weight learnt would decrease.
- However, this embedding needs to combine with the positional encoding (with increasing integer number). To have roughly same scale of value, \(\sqrt{d_{model}}\) is multiplied.
3.5 Positional Encoding
As discussed in previous section, attention mechanism itself are operations on sets. In other words, changing the order of encoder input would not affect its output.
To add sequence information, we applied "positional encoding". In transformer, sine and cosine functions of different frequencies are used.
\[ \begin{aligned} PE_{(pos,2i)}=&sin(pos/10000^{2i/d_{model}})\\ PE_{(pos,2i+1)}=&cos(pos/10000^{2i/d_{model}})\\ &\text{where pos is position and i is dimension} \end{aligned} \]
4. Why self-attention?
Comparison between self-attention layers to the recurrent and convolutional layers on seq2seq tasks.
Self attention is evaluated on three criteria (as following column):
Computation speed
Amount of parallelizable computation (smaller \(O(x)\) the better)
Path length of signals have to traverse in the network between long range dependencies.
“The shorter these paths between any combination of positions in the input and output sequences, the easier it is to learn long-range dependencies."
| Layer Type | Complexity per Layer | Sequential Operation | Maximum Path Length |
|---|---|---|---|
| Self-Attention | \(O(n^2\cdot d)\) | \(O(1)\) | \(O(1)\) |
| Recurrent | \(O(n\cdot d^2)\) | \(O(n)\) | \(O(n)\) |
| Convolutional | \(O(k\cdot n\cdot d^2)\) | \(O(1)\) | \(O(log_k(n))\) |
| Self-Attention(restricted) | \(O(r\cdot n\cdot d)\) | \(O(1)\) | \(O(n/r)\) |
\(n\) - input sequence length, \(d\) - the representation dimensionality, \(k\) - kernel width, \(r\) - restricted neighborhood size
- \(n\) is normally smaller than \(d\), giving self-attention advantages in computing.
- \(k\) is usually a small number, therefore CNN & RNN has roughly same level of complexity.
- Adding restriction to self-attention is a trade-off between capturing long range dependencies and computation speed.
5. Training
In this section, training regime is described.
Encode setting - byte-pair encoding
Dataset - larger WMT 2014 English-French dataset consisting of 36M sentences
Batch - a set of sentence pairs with approximately 25000 source tokens and 25000 target tokens
Hardware - 8 NVIDIA P100 GPUs (still affordable, compared to GPT :P)
- TPU is implemented afterwards to facilitate transformer like computation (with large matrix multiplication)
Time
- Base model - 0.4s step time,100,000 steps / 12 hours
- big model - 1.0s step time, 300,000 steps / 3.5 days
Optimizer
- Adam, \(\beta_1=0.9,\beta_2=0.98,\epsilon=10^{-9}\)
Scheduling
- \(lrate = d^{-0.5}_{model} \cdot min(step\_num^{-0.5}, step\_ num \cdot warmup\_steps^{-1.5})\)
- "This corresponds to increasing the learning rate linearly for the
first
warmup_stepstraining steps, and decreasing it thereafter proportionally to the inverse square root of the step number. We used warmup_steps = 4000."
Regularization
- Residual dropout
- output of each sub-layer, sums of the embeddings and the positional encodings in both the encoder and decoder stacks.
- \(P_{drop}=0.1\)
- Label smoothing
- value \(\epsilon_{ls}=0.1\)
- hurts perplexity, but improves accuracy & BLUE score.
- Residual dropout
6. Results
In this section, results on machine translation (English-to-German), different model architecture, English Constituency Parsing tasks are summarized.
7. Conclusion
- Transformer - "The first sequence transduction model based entirely on attention"
- Achieved a new state of the art on machine translation task
- Proposing a new model architecture for handling multi modalities & adapting to different downstream tasks (see more in BERT)