In this post, I would provide an introduction to Knowledge graph, provide information about its definition, construction, storage and application.
Definition
What is Knowledge Graph (KG)?
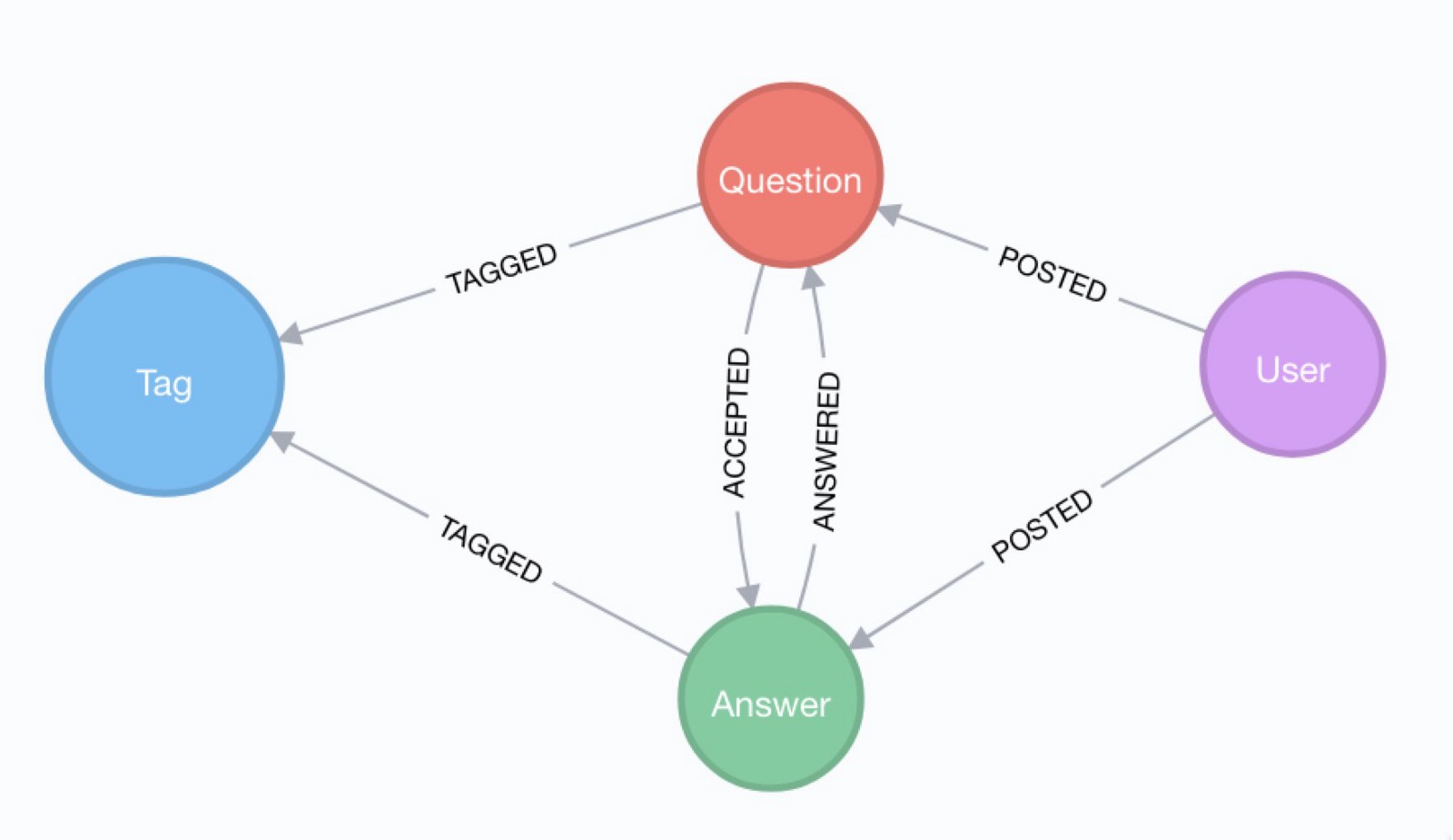
- Knowledge graph is a symbolic, structured semantic network used to store entities and their relations.
Basic Components
- Entity
- The node in knowledge graph. Used to represent people, events or
things.
- The node in knowledge graph. Used to represent people, events or
things.
- Relation
- The edge in knowledge graph. Used to represent relations between
defined entities.
- The edge in knowledge graph. Used to represent relations between
defined entities.
- Property
- Additional information attached to node or relation.
Examples
Based on different context, entity and relations could be varied. Below are three examples for possible designs.
Medical KG
- Entity - Disease, Drug, Food, Cure method, Department
- Relation
- Disease --[recommend_use]--> drug
- Disease --[recommend_eat]--> food
- Disease --[accompany_with]--> Disease
- Disease --[recommend_use]--> drug
- Property
- Disease - cause, cure_last_time, susceptible_groups,...
Financial KG
- Entity - Company, Person (Management), Fund, Industry
- Relation
- Company --[has_manager]--> Person
- Company --[in_industry]--> Industry
- Company --[has_manager]--> Person
User Profile KG
- Entity - User, Event (could be further divided to different
categories based on user's interaction / data gathered), Company
- Relation
- User --[is_friend | is_lover]--> User
- Event --[]--> User
- User --[work_for]--> Company
- Property
- User - name, gender, occupation, preferences
- Event - name, type, start/end_time, type_specific_information
- User - name, gender, occupation, preferences
- User --[is_friend | is_lover]--> User
Construction
Data Access
- Use open-source data or web-crawlers.
Information Retrieval
- Used for processing unstructured / semi-structured data by
extracting useful information via NLP methods, which includes:
- Sentence segmentation
- Tokenization
- Part Of Speech (POS) tagging
- Named Entity Recognition
- Relation Retrieval
- Sentence segmentation
Knowledge Fusion
- Used for intergrate incoming data and existing knowldge graph.
Knowledge retrieved may contain inaccurate or redundant information, Coreference Resolution (to solve ambiguity brought by pronouns) and Entity Disambiguation (combine aliases for one thing) could be used to improve the quality of knowledge map.
Knowledge Process
- Used for discovering new relations.
- E.g. User Profile KG, users with identical properties may share similar preferences.
The technology involed is called Knowledge Inference, which could be implemented using logic / graph algorithm / deep learning.
Storage
RDF (Resource Description Framework)
Text format, easy modification, poor readability
A glimpse of RDF file (from this repo):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:owl="http://www.w3.org/2002/07/owl#"
xmlns:asset="http://www.daedafusion.com/Asset#"
xmlns:xsd="http://www.w3.org/2001/XMLSchema#"
xmlns:edt="http://www.daedafusion.com/editor_annotation#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xml:base="http://www.daedafusion.com/Asset">
<owl:Ontology rdf:about="">
<owl:imports rdf:resource="http://www.daedafusion.com/editor_annotation"/>
<rdfs:label xml:lang="en-US">ARGOS Asset Ontology</rdfs:label>
<rdfs:comment xml:lang="en-US">Editor Annotation ontology defines a set of annotations that provide a graphical editor information about how to create corresponding IRI's for new instances created along with information that is used to control how properties appear in the editor.
Copyright (c) 2014, DaedaFusion, LLC. All rights reserved.</rdfs:comment>
<owl:versionInfo rdf:datatype="http://www.w3.org/2001/XMLSchema#string"
>1.0.0.0</owl:versionInfo>
</owl:Ontology>
<owl:Class rdf:ID="Asset">
<rdfs:subClassOf>
<owl:Restriction>
<owl:cardinality rdf:datatype="http://www.w3.org/2001/XMLSchema#nonNegativeInteger"
>1</owl:cardinality>
<owl:onProperty>
<owl:DatatypeProperty rdf:ID="mimeType"/>
</owl:onProperty>
</owl:Restriction>
</rdfs:subClassOf>
<rdfs:comment xml:lang="en-US">Characterizes a digital asset</rdfs:comment>
<rdfs:label xml:lang="en-US">Asset</rdfs:label>
<rdfs:subClassOf rdf:resource="http://www.w3.org/2002/07/owl#Thing"/>
<edt:namespacePrefix rdf:datatype="http://www.w3.org/2001/XMLSchema#string"
>argos</edt:namespacePrefix>
<rdfs:isDefinedBy rdf:resource=""/>
</owl:Class>
<owl:ObjectProperty rdf:about="#locatorURI">
<rdfs:comment xml:lang="en-US">Specifies the location from where the asset was ingested</rdfs:comment>
<edt:namespacePrefix rdf:datatype="http://www.w3.org/2001/XMLSchema#string"
>argos</edt:namespacePrefix>
<rdfs:label xml:lang="en-US">Location URI</rdfs:label>
<rdfs:domain rdf:resource="#Asset"/>
<rdfs:isDefinedBy rdf:resource=""/>
<rdfs:range rdf:resource="http://www.w3.org/2002/07/owl#Thing"/>
</owl:ObjectProperty>
</rdf:RDF>
Graph Database - A more common practice
- Database format, Cypher modification, Good readability & usability
Applications
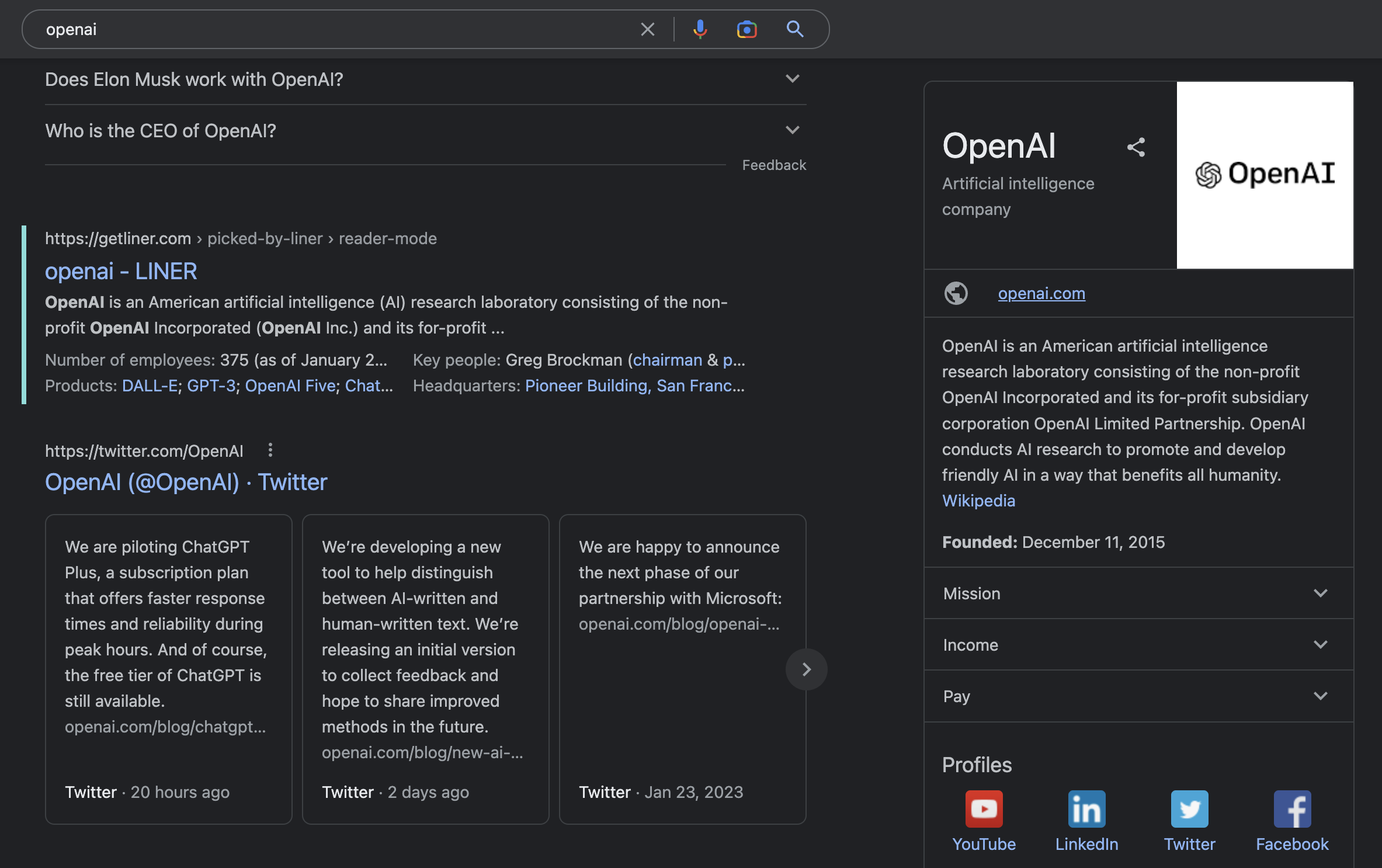
Search Engine / (KG)QA system
QA system, query KG to find answers for a problem
Google's example, answer combined with KG (the left card)
Conversational AI
Resources
General Evaluations
- Pros
- Little comprehension difficulty
- Structured and explicit data for customized domain
- Ability to support different purposes (knowledge query via KGQA, knowledge discovery via inference)
- Cons
- Difficult to migrate to other domain
- Intensive data & detailed process needed
- As graph grows larger, efficiency may become a problem