In this article, I will provide a walkthrough of common features on stable diffusion webui's txt2img tab and how to use them to produce better quality pictures as you wish.
Common Parameters
Below is a screenshot of stable diffusion web ui. I will walk through this interface left-to-right, top-to-bottom.
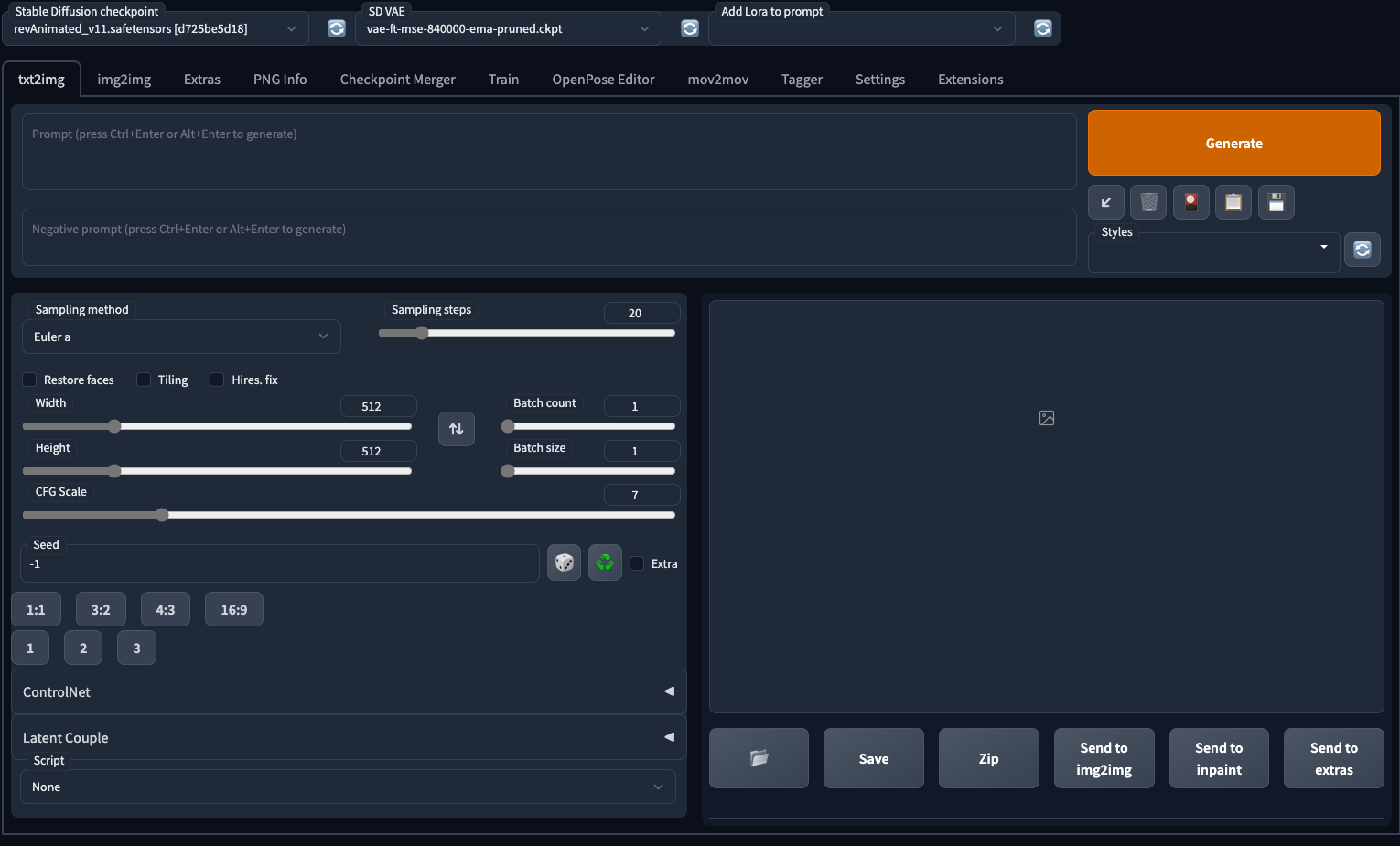
P.S. If you want to set your web ui to dark theme, you could either change your website url to
your_url_goes_here/?__theme=darkor pass a parameter when launching webui bypython launch.py --theme dark
Checkpoints
Checkpoints (or more commonly referred as models) provide customizations for different styles.
Why there are different checkpoints?
Checkpoints are further trained on the base diffusion model provided by stability AI to obtain better results with high quality images or enhance the performance on certain styles.
For example, I used a model called Realistic Vision, which is optimized for real photo generation and provides better results compared to the base model.
Pick your model up on civitai and
put it under stable-diffusion-webui/models/stable-diffusion
folder to load.
- A list of recommended models
- Realistic Vision - for photography like, realistic images
- deliberate - A great model for general purpose, with sufficient tags, you could get great results ranging from 2.5D images to 2D animation style images or even flat illustration images.
VAE
P.S. I modified the settings to bring up these two selections, if you are interested, check Settings >
VAE stands for variational autoencoder, which transform the images from latent place (the computer/model representation of images) to human-readable format.
A wonderful tutorial could be found here. I would share a comparison of using or not using VAE in a later advanced usage post.
LoRA
LoRA stands for Low-Rank Adaptation, which is actually a technique used to fine-tune large language models (LoRA paper). In this context, you could treat LoRA as a smaller version of checkpoints which provide style guide or particular character guide. You could also find LoRA on civitai.
Prompt
The cue passed to model for image generation, this is the most important part during generations.
- Separated into 2 parts in webui:
- positive prompt (what you want)
- negative prompt (what should be avoid)
How to write good prompts?
Prompt could be roughly divided into two parts based on word count: textual descriptions and tags.
- Different models have different support for the two categories’ prompt input. Different models may even have different weights on a same tag. It’s better to check the models’ description and example prompts from community to better your generations.
Format
()- multiply the weights of enclosed tag(s) by 1.1, could be nested((tag)).[]- divide the weights of enclosed tags by 1.1.:- used directly after the tag to define the weights,e.g.pink:1.4
For more formatting guides, check the webui wiki page.
Templates for textual descriptions
Descriptions are normally a sentence, describing the subject, the on-going event, the type of pictures, etc.
“A [type of picture] of a [main subject], *[style cues]**” Ref
- E.g.A portrait of a 25 y.o. young man, uhd
Tags
Tags are short, symbolic words that represents a specific type of image or element. It could be roughly divided into 3 categories:
Quality tags: like
masterpiece,highres(high resolution),best quality. UsuallyContent tags: restrict the content of the image,
1girl,RAW photoin positive prompts ormutated hands,missing fingersin negative promptsSubject tags: clearly defines what the subject should be like. For example, when generating a anime character, tags like
black hair,yellow eyes,lab coat,standing,looking at viewercould be used for precise generation in terms of appearance, clothing and pose.P.S. Despite using tags, ControlNet could be another way to control the pose for character generation. Please wait for my advanced tutorial post, or check this wonderful video tutorial first.
Commonly used tags
Positive tags:
masterpiece,1girl,highres,ultra detail, etc.Discover the tags that fits your need on Diffusion Model site's example prompts.
Or found interesting prompts use the search engine
Style tags/templates - Realistic
Image - RAW photo, 8k uhd
- Postive Prompts
1
RAW photo, *subject*, (high detailed skin:1.2), 8k uhd, dslr, soft lighting, high quality, film grain, Fujifilm XT3
- Negative Prompts
1
(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime:1.4), text, close up, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck
- Commonly used negative tags:
1
lowres, ((bad anatomy)), ((bad hands)), text, missing finger, extra digits, fewer digits, blurry, ((mutated hands and fingers)), (poorly drawn face), ((mutation)), ((deformed face)), (ugly), ((bad proportions)), ((extra limbs)), extra face, (double head), (extra head), ((extra feet)), monster, logo, cropped, worst quality, low quality, normal quality, jpeg, humpbacked, long body, long neck, ((jpeg artifacts))
Take aways - Ref
Anything unspecified may be randomly generated
- Sometimes even said ones could be interpreted wrongly. Try to
increase the tag's weight using the format
(style_or_attribute_name: 1.x), this would assign a weight1.xto the specified tag.
- Sometimes even said ones could be interpreted wrongly. Try to
increase the tag's weight using the format
Try visually well-defined objects
- E.g. Wizard, priest, angle, rockstar, temple, farm, etc.
Try describing a style
- Try: cyberpunk, psychedelic, surreal, vaporwave, alien, solarpunk, modern, ancient, futuristic, retro, realistic, dreamlike, funk art, abstract, pop art, impressionism, minimalism
Try invoking unique artists for style (deprecated in stable-diffusion-2.0)
- Try: Hiroshi Yoshida, Max Ernst, Paul Signac, Salvador Dali, James Gurney, M.C. Escher, Thomas Kinkade, Ivan Aivazovsky, Italo Calvino, Norman Rockwell, Albert Bierstadt, Giorgio de Chirico, Rene Magritte, Ross Tran, Marc Simonetti, John Harris, Hilma af Klint, George Inness, Pablo Picasso, William Blake, Wassily Kandinsky, Peter Mohrbacher, Greg Rutkowski, Paul Signac, Steven Belledin, Studio Ghibli
Try different medium (the type of picture)
- Try: painting, drawing, sketch, pencil drawing, woodblock print, matte painting, child's drawing, charcoal drawing, an ink drawing, oil on canvas, graffiti, watercolor painting, fresco, stone tablet, cave painting, sculpture, work on paper, needlepoint
Avoid indirect (e.g.
a hat that is not red), use positive term (e.g.a blue hat)Use this site to get visual cue for generating prompts on different styles.
Buttons
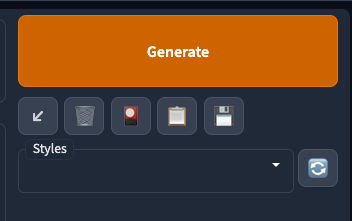
Generateis obvious. You need to click on something to execute!The arrow ↙ stands for reading parameter from your prompt. Amazingly useful when copied generation data from civitai.
- When the prompt input are empty, it will read the settings for last generation.
🗑️ clears your current prompt
The middle button would open up a sub element to allow you set
textual embeddings,lora, etc.The fourth button would copy your styles’s prompt into the box on the left hand side.
The fifth button are used to save styles (or templates) for your generation. Only supports prompts.
But you can save generation data into prompt, which can be found after generation in the bottom right corner.
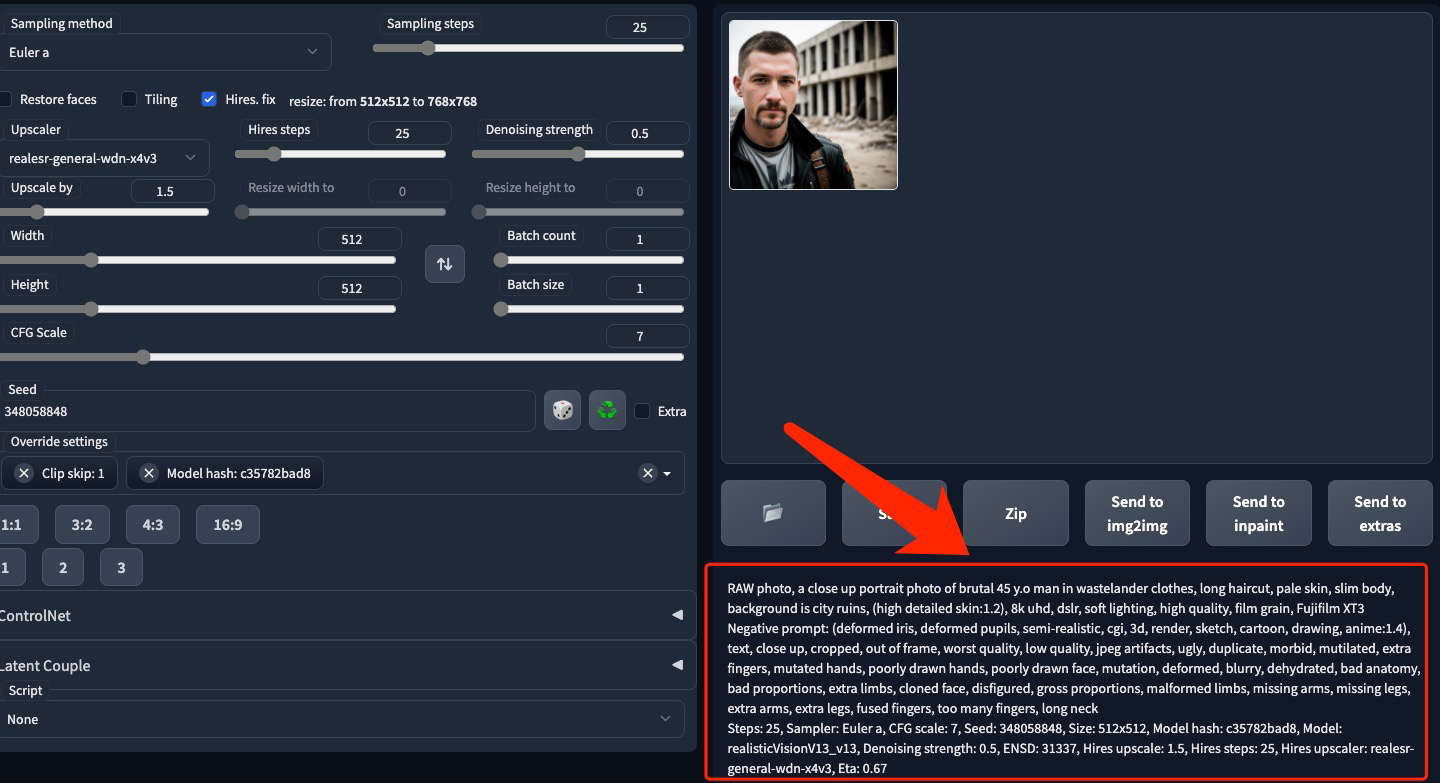
Styles (templates) are pre-defined prompts + parameter settings to help you quickly recover from your previous work / save combinations of model settings.
Sampling Methods
Sampling methods are the algorithms used to produce images.
- Even though I used stable diffusion for some time, I could hardly tell a definitive difference between different samplers.
- It is suggested to use the same sampler as the model's example
prompt does, or use popular ones like
Euler a,DDIM,DPMfamily. With time permitting, give every sampler a try. - Below is a comparison image for different sampling methods. Ref
for samples’ job

Sampling steps
Number of steps used to generate images. Larger number takes longer
to generate. Normally set between 20~80
- Note: Not bigger value the better. Some sampling methods' performance does not increase as the value increases.
Restore Face
Help fix deformed faces when generating characters. Need to download the model when used first time.
Tiling
Not yet used.
Hires Fix
Stands for high resolution fix, which upscales the generated image to a larger resolution. When clicked, it would give you additional parameter options like below.
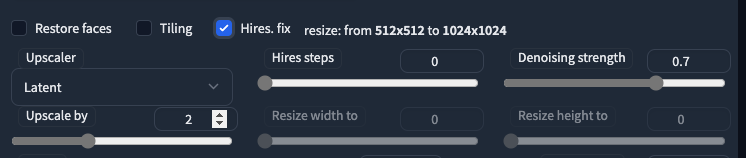
Upscaleris like sampling methods, which defines how to generate the image. Different types of images may need different types of upscaler, check this thread from reddit - The DEFINITIVE Comparison to Upscalers : StableDiffusionHires stepsare like sampling steps. However, for some model it could be set to0.Denoising strengthis an important parameters used in image to image. It defines to what extent should the upscaler respect the original image.Upscale byis a factor that would allow you customized your final image’s resolution after up-scaling.
Resolution
Weight and Height controls the output
image’s resolution.
- Higher resolution would take up more VRAM on your graphic card.
- Normal ratio of images (like 512x512, 512x768, 768x512) performs better than weird resolution since the model was trained on images with normal ratio.
CFG scale
Classifier Free Guidance scale - Restricts how strongly the generated
image should conform the prompt. It is most commonly set to values
between 6-9. It is better to modify a specific tag’s
weights if you found the some part of the generation went wrong.
- Lower values -> less restricted / more creative result
Batch count
Specify how many batches to generate. Using this parameter to create multiple images with same prompt setting.
Batch size
- Specify how many image to create in a single batch.
- High VRAM needed. For consumer level graphics card, it's better to increase the batch count for multiple generations. (Trade VRAM space with time)
Seed
A random variable that controls the output.
- With same settings (including seed), you could reproduce the result.
Others
I would leave Controlnet and scripts for a later post~
Wonderful Video Tutorials
- Stable
Diffusion-Master AI Art: Installation, Prompts, txt2img-img2img,
out/inpaint &Resize Tutorial - By ChamferZone
- A Comprehensive tutorial for using stable diffusion through web-ui.
- Tutorials by Sebastian Kamph, really brief but useful snippets. I enjoyed the ControlNet tutorial a lot, really mind blowing!