In this article, I will give an overall introduction about recommenders, including how the recommendation problem arises, the abstract models and the key problems when building a new recommender.
Background
As we step into the information era, there are a increasing number of products, movies, music, short videos, etc. that is either virtual content itself or was provided online shopping option instead of onsite. This paradigm shift from scarcity to abundance took place as virtual content provider and online stores gained more advantages in the cost of inventory storage and distribution compared to traditional retailers (onsite shops).
We have developed two ways to interact with these abundant virtual catalogues, which are:
- Search (When the user know what they want to find)
- Recommendation (when the user does not know what they want to find)
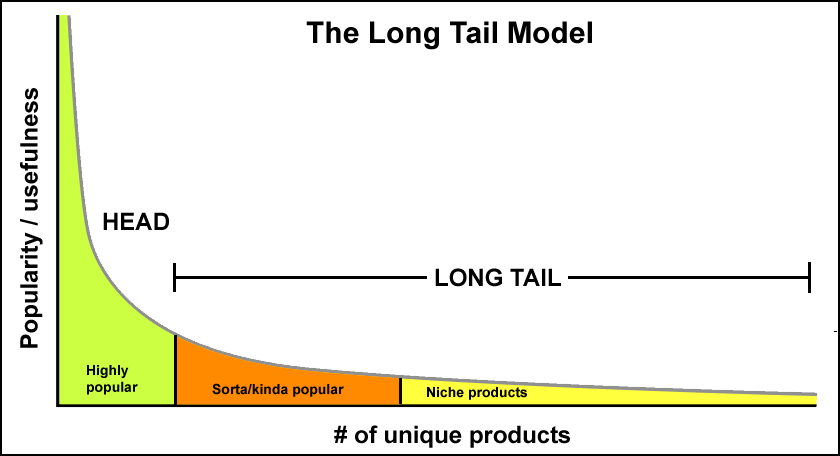
Since there seems to be more profit by selling small volumes of hard-to-find items to many customers (the long tail part) instead of only selling large volumes of a reduced number of popular items (the head part), companies are refining their business strategy based on the Long Tail model (as described in the image below). That is to say, by customizing the content (in the long tail) presented to the user, increase the chance of product sell or consumption. This requirements necessitates better filters, that is to say, the Recommender or recommendation system.
Types of recommenders
There are several general types of recommenders arose under different context:
Editorial and hand curated
Some example of this type of recommendation includes "List of favorites", "List of essentials".
This type of recommender has a significant drawback: there is no input from the user sides. The recommendation relies entirely on the selection of the website editor, and there is no usage of the user interaction data. So this approach is not used in modern application with a lot of user generated content and data.
Simple aggregates
Examples of these aggregates includes "Top 10 XXX", "Most popular", "Recent uploads", etc.
This type of recommender simply perform some grouping actions on the consumption data, but it is still not customized to specific users. However, this approach is useful to deal with the Cold Start problem when a new user joined with no previous interaction data, so you could still see these sections in applications today.
Tailored to individual users
This is the type of recommender that most applications used today by taking individual user's interaction as input and output content tailored to their taste, which I will to discuss further in future posts.
General models
When defining later recommenders, we usually have a structure with the following data:
- \(C\) = set of Customers
- \(S\) = set of Items
- Utility function \(u: C\times S
\rightarrow R\)
- \(R\) = set of ratings ( is a
totally ordered set)
- E.g. 0-5 stars, real number in
[0,1]
- E.g. 0-5 stars, real number in
- \(R\) = set of ratings ( is a
totally ordered set)
- Utility matrix - \(U\) = the matrix
form of the above utility function.
- Usually we have items listed on columns, user listed on rows, where the entry \((i,j)\) corresponds to the user \(i\)'s rating on \(j\)-th item.
Key problems
By defining the general models above, we could derive some of the key problems that we need to handle when building recommenders.
1. Gathering "known" ratings to form the utility matrix
The problem is then - How to collect the data in the utility matrix? We need to take the cold start problem into consideration. That is to say, for new items with no ratings or for new users with no history, we need to derive different strategies.
For example, some applications may let you choose the area you are interested in during the registration process. More and more new item are now tagged with genre / producer / director / actor all kinds of metadata to help it fit into the current database.
To solve the collection problem mentioned above, the industry has two types of solutions:
Explicit
That's ask people to rate items after purchase or consumption. This is a very direct way to get ratings, however it has the drawback of it doesn't scale as not many users would like to provide ratings or detailed feedback.
Implicit
To handle the scaling aspect of the data, industry (based on their products) have designed various algorithms to interpret ratings from user interactions. For example, companies like TikTok will track the type of videos that you like to view more and perform corresponding recommendation. Nevertheless, it is still hard to learn low ratings (as users tend not to interact with items they dislike).
2. How to extrapolate "unknown" ratings from the known ones?
This is the key part of "recommendation" where the system based on past user interaction data to infer user's most likely interested items and present it. It is also the main focus of different recommender architecture and algorithms. For example, there are recommendation methods like and will be discussed in later posts: - Content-based filtering - Collaborative filtering - Model-based filtering
3. How to evaluate extrapolation methods?
With the two above questions answered, we need to evaluate the performance of the recommender we built to guide us better iterated the model and algorithm. Some of the popular metrics includes:
- Accuracy Metrics: Measures how closely the
recommendations match user preferences.
- Mean Absolute Error (MAE): Average absolute difference between predicted and actual ratings.
- Root Mean Square Error (RMSE): Square root of the average squared differences between predicted and actual ratings.
- Precision and Recall: Precision measures the proportion of recommended items that are relevant, while recall assesses the proportion of relevant items that are recommended.
- Diversity Metrics: Evaluates how varied the
recommendations are.
- Intra-List Diversity: Diversity within a list of recommendations.
- Item Coverage: Range of different items recommended across all users.
- Scalability and Efficiency: Analyzes the system's
performance as the dataset size increases.
- Response Time: Time taken to generate recommendations.
- Throughput: Number of recommendations generated per unit time.
- User Satisfaction: Subjective measure through user
studies or feedback.
- User Surveys: Collecting direct feedback from users about their satisfaction with the recommendations.
- Usage Metrics: Monitoring user interaction with the system, like click-through rates.