SQL (Structured Query Language) is the backbone of relational databases. This guide breaks SQL into its five command types—DQL, DML, DDL, DCL, TCL.
What is SQL?
Structured Query Language (SQL) is a standard computer language created for accessing and manipulating relational databases like MySQL, Oracle, SQL Server, PostgreSQL, etc.
SQL could perform the below commands on relational databases:
- Retrieve and filter data
- Insert, update, and delete records
- Create and modify database structures
- Manage permissions and transactions
Commands
| Category | Name | Purpose | Examples |
|---|---|---|---|
| DDL | Data Definition Language | Create or modify database structures | CREATE, ALTER, DROP,
TRUNCATE |
| DQL | Data Query Language | Query data | SELECT |
| DML | Data Manipulation Language | Manage data | INSERT, UPDATE, DELETE |
| DCL | Data Control Language | Manage access and permissions | GRANT, REVOKE |
| TCL | Transaction Control | Manage transactions | COMMIT, ROLLBACK,
SAVEPOINT |
Note: DCL and TCL is not covered in this post.
Syntax
- SQL is case-insensitive:
SELECTandselectare identical. - Some database systems require a semicolon (
;) at the end of each SQL statement.- A semicolon is the standard way to separate SQL statements in database systems, enabling multiple statements to be executed in a single request to the server.
- SQL uses single quotes (
' ') to enclose text values. - Comments:
- Single-line:
-- - Multi-line:
/* */
- Single-line:
Data Query Language - DQL
SELECT
To retrieve data you use the command SELECT. At its
core, you select the columns you want to
see from the table they're contained in.
1 | |
1 | |
Use sub-clause to narrow down the rows
WHERE
WHERE are used for filtering result table.
Basic Syntax:
SELECT column1, column2,... FROM table_name WHERE condition;
To write a condition, we can use the below operator to form an expression.
| Operator | Description | e.g. |
|---|---|---|
| = | equal | column=value |
| <> | not equal. In some version could be != | column<>value |
| > | larger than | column > value |
| < | smaller than | column < value |
| >= | larger or equal to | column >= value |
| <= | smaller or equal to | column <= value |
| BETWEEN... AND | filter values within the range | column between a and b |
| LIKE | search for a pattern (most common for strings) | column LIKE '%k' (ending with k) |
| IN | multiple possible values for a column | column IN (value1, value2, ...) |
ORDER BY
ORDER BY are used to sort the result table. The table is
sorted in ascending order by default. When sorting by
multiple columns, the order of columns affects the
result. The sorting is performed on column1 first,
and then column2 is sorted based on the order
preserved by column1.
Basic Syntax: 1
2
3SELECT column1, column2, ...
FROM table_name
ORDER BY column1, column2, ... ASC|DESC;
GROUP BY
GROUP BY are used together with aggregation function: -
AVG() - return the average - COUNT() - return
the number of occurrence - FIRST() - return the first
record - LAST() - return the last record -
MAX() - return the maximum value - MIN() -
return the minimum value - SUM() - return the sum
Basic Syntax: 1
2
3
4SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;
HAVING
HAVING 's usage is just like WHERE, the
main difference is WHERE filters rows in the table, while
HAVING filters groups.
Therefore, we can have a below query, we want to list suppliers who supply two or more products, each priced at 10 or more.
1 | |
JOIN
To retrieve data from multiple tables, we use
command JOIN to combine records from different tables and
use ON to indicate columns for the seam.
1 | |
1 | |
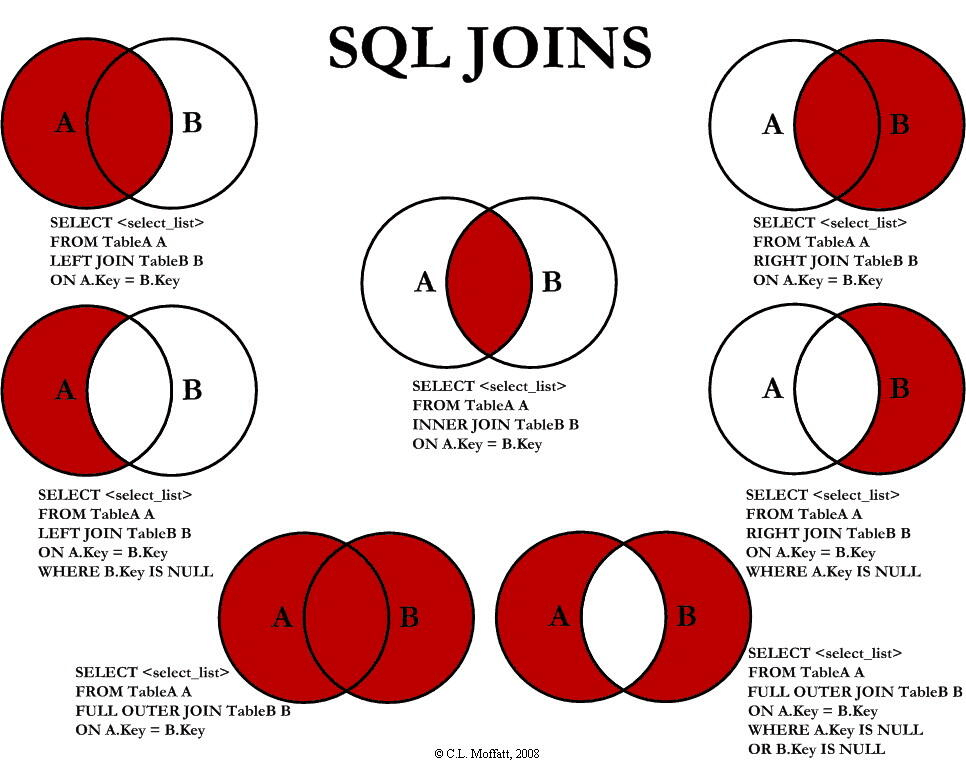
| Type | Description |
|---|---|
| INNER JOIN | Returns records that match in both tables (intersection). |
| LEFT JOIN | Returns all records from the left table, with matched records from the right table (preserves left table). |
| RIGHT JOIN | Returns all records from the right table, with matched records from the left table (preserves right table). |
| FULL OUTER JOIN | Returns all records from both tables, including unmatched ones (union). |
| CROSS JOIN | Returns the Cartesian product: each row from the left table paired with each from the right. |
| SELF JOIN | Joins a table with itself. |
| NATURAL JOIN | Automatically joins tables using columns with the same name in both. |
Data Definition Language - DDL
CREATE
The SQL CREATE statement is used to define new
database objects. The most common forms are:
- Create a Table
1
2
3
4
5CREATE TABLE table_name (
column1 datatype [constraints],
column2 datatype [constraints],
...
);
- Defines a new table with specified columns, types, and optional
constraints (e.g.
PRIMARY KEY,NOT NULL).
- Create a Database
1
CREATE DATABASE database_name;
- Initializes a new database.
- Create an Index
1
2CREATE INDEX index_name
ON table_name (column1, column2, ...);
- Improves query performance by indexing specific columns.
Constraints
Constraints ensure data integrity and include rules like uniqueness, foreign keys, and more.
Primary Key
1
2ALTER TABLE table_name
ADD CONSTRAINT pk_name PRIMARY KEY (column1, column2);Foreign Key
1
2
3
4ALTER TABLE child_table
ADD CONSTRAINT fk_name FOREIGN KEY (column)
REFERENCES parent_table(parent_column)
ON DELETE CASCADE;Unique
1
2ALTER TABLE table_name
ADD CONSTRAINT unique_name UNIQUE (column);
ALTER
The SQL ALTER statement is used to modify an existing
database object, typically a table. It allows changes
to the table’s structure without deleting or recreating it.
Common Uses of ALTER TABLE
- Add a column:
1
ALTER TABLE table_name ADD column_name datatype; - Drop a column:
1
ALTER TABLE table_name DROP COLUMN column_name; - Rename a column (syntax varies by DBMS):
1
ALTER TABLE table_name RENAME COLUMN old_name TO new_name; - Change column datatype:
1
2ALTER TABLE table_name MODIFY column_name new_datatype; -- MySQL
ALTER TABLE table_name ALTER COLUMN column_name TYPE new_datatype; -- PostgreSQL - Rename table:
1
ALTER TABLE old_name RENAME TO new_name; - Add/remove constraints:
1
2ALTER TABLE table_name ADD CONSTRAINT ...;
ALTER TABLE table_name DROP CONSTRAINT constraint_name;
DROP
The DROP statement in SQL is used to permanently
delete a database object such as a table,
database, view, or
index. Once dropped, the object and all its data are
lost and cannot be recovered (unless backed up).
Common Syntax: 1
2
3
4DROP TABLE table_name;
DROP DATABASE database_name;
DROP VIEW view_name;
DROP INDEX index_name ON table_name;
- Use with caution—
DROPremoves both schema and data. - Some RDBMS (like PostgreSQL) support
IF EXISTSto avoid errors if the object doesn't exist:1
DROP TABLE IF EXISTS table_name;
TRUNCATE
TRUNCATE in SQL is a data
definition language (DDL) command used to quickly remove
all rows from a table without logging
individual row deletions.
Key points: - Faster than DELETE
(especially for large tables). - Cannot be rolled back
in most RDBMS once committed. - Resets auto-increment
counters in some databases (e.g., MySQL). - Cannot use WHERE
clause—it always affects the entire table.
Syntax:
1 | |
Data Manipulation Language - DML
INSERT
SQL INSERT is used to add new rows to a
table.
Basic Syntax: 1
2INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...);
Variants: 1. Insert all columns (in order):
1
2INSERT INTO employees
VALUES (1, 'Alice', 'Engineering');1
2INSERT INTO employees (name, department)
VALUES ('Bob', 'HR');1
2INSERT INTO employees (name, department)
VALUES ('Carol', 'Finance'), ('Dave', 'IT');1
2INSERT INTO archive_employees (id, name)
SELECT id, name FROM employees WHERE department = 'HR';
UPDATE
The SQL UPDATE statement modifies existing
records in a table.
Basic Syntax: 1
2
3UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
Key Points: - Without a WHERE clause,
all rows will be updated. - You can update one or
multiple columns. - Can use expressions or subqueries for the new
values.
Example: 1
2
3UPDATE employees
SET salary = salary * 1.1
WHERE department = 'Sales';
DELETE
DELETE in SQL is used to remove rows
from a table.
Basic Syntax: 1
DELETE FROM table_name WHERE condition;
Key Points: - Removes specific rows
matching the WHERE clause. - If WHERE is
omitted, all rows in the table are deleted. - To avoid
deleting everything by mistake, always use a WHERE
clause unless intentional.
Example: 1
DELETE FROM Employees WHERE Department = 'Sales';